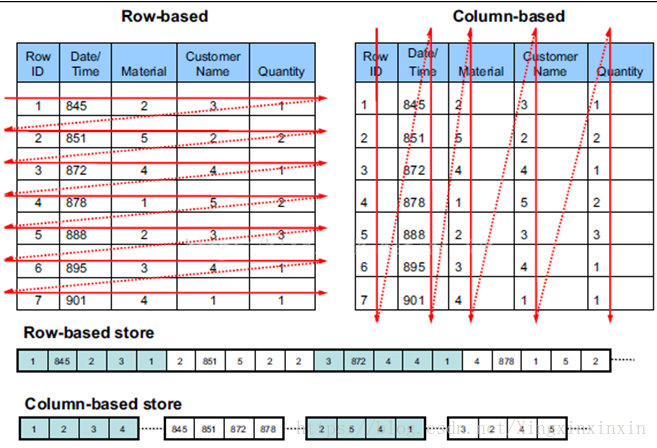
列存储
在常见的OLTP中,大部分都是按行存储的,在OLAP中,如果数据行特别多,可以考虑列存储。
应用场景
一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。 列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。
优点
- 同一个数据列的数据类型相同,数据相似性高,列式数据库压缩性比行存储好。
- 使用什么压缩算法?
- 若字段属性并不多,可以替换;位图的压缩方法;具体参考这里
- 查询单列只需扫描单列,不必加载整行数据
- 缓存命中率提高,这是因为同一列的数据被高度压缩,常用的Page被频繁访问而变得异常活跃,Buffer Manager把活跃的数据页缓存到内存中,不常用的Page被换出(Page Out)
在UDW中使用列存储
首先进入UDW:
psql -U dyt -h udw.lurymd.m0.service.ucloud.cn -p 5432 -d db_dyt -W
创建列存储表
create table test_column_ao(
id bigint,
name varchar(128),
value varchar(128)
)with(appendonly=true,ORIENTATION=column,compresslevel=5)
distributed by (id);
查看表结构:

导入数据
使用同一个数据源,分别进行行存储和列存储:
create table r_table (
id int,
col1 int,col2 int,col3 int,col4 int,col5 int,col6 int,col7 int,col8 int,col9 int,col10 int,
col11 varchar(10),col12 varchar(10),col13 varchar(10),col14 varchar(10),col15 varchar(10),
col16 varchar(10),col17 varchar(10),col18 varchar(10),col19 varchar(10),col20 varchar(10),
col21 varchar(20),col22 varchar(20),col23 varchar(20),col24 varchar(20),col25 varchar(20),
col26 varchar(20),col27 varchar(20),col28 varchar(20),col29 varchar(20),col30 varchar(20),
col31 varchar(30),col32 varchar(30),col33 varchar(30),col34 varchar(30),col35 varchar(30),
col36 varchar(30),col37 varchar(30),col38 varchar(30),col39 varchar(30),col40 varchar(30),
col41 varchar(40),col42 varchar(40),col43 varchar(40),col44 varchar(40),col45 varchar(40),
col46 varchar(40),col47 varchar(40),col48 varchar(40),col49 varchar(40),col50 varchar(40),
col51 varchar(50),col52 varchar(55),col53 varchar(60),col54 varchar(65),col55 varchar(128),
col56 date,col57 text,col58 timestamp,col59 varchar (125),col60 bigint)
with (appendonly=true,compresslevel =5)
distributed by (col11);
create table c_table (
id int,
col1 int,col2 int,col3 int,col4 int,col5 int,col6 int,col7 int,col8 int,col9 int,col10 int,
col11 varchar(10),col12 varchar(10),col13 varchar(10),col14 varchar(10),col15 varchar(10),
col16 varchar(10),col17 varchar(10),col18 varchar(10),col19 varchar(10),col20 varchar(10),
col21 varchar(20),col22 varchar(20),col23 varchar(20),col24 varchar(20),col25 varchar(20),
col26 varchar(20),col27 varchar(20),col28 varchar(20),col29 varchar(20),col30 varchar(20),
col31 varchar(30),col32 varchar(30),col33 varchar(30),col34 varchar(30),col35 varchar(30),
col36 varchar(30),col37 varchar(30),col38 varchar(30),col39 varchar(30),col40 varchar(30),
col41 varchar(40),col42 varchar(40),col43 varchar(40),col44 varchar(40),col45 varchar(40),
col46 varchar(40),col47 varchar(40),col48 varchar(40),col49 varchar(40),col50 varchar(40),
col51 varchar(50),col52 varchar(55),col53 varchar(60),col54 varchar(65),col55 varchar(128),
col56 date,col57 text,col58 timestamp,col59 varchar (125),col60 bigint)
with (appendonly=true,ORIENTATION=column,compresslevel =5)
distributed by (col11);
导入数据
\copy r_table from '/home/cl/columnstore/data.dat' with delimiter ',';
\copy c_table from '/home/cl/columnstore/data.dat' with delimiter ',';
查询比较
比较存储大小
select pg_relation_size('c_table')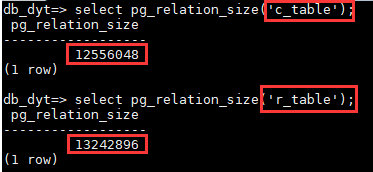
首先用
\timing on开始计时查询10个字段消耗的时间
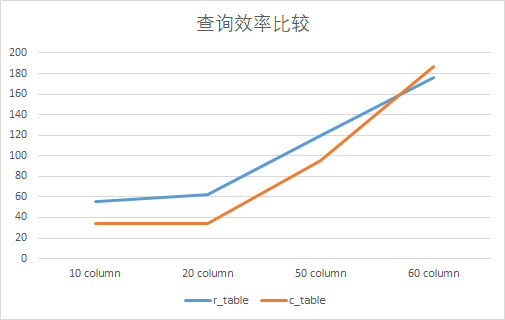
select count(col1),count(col5),count(col10),count(col20),count(col25),count(col32),count(col42),count(col45),count(col56),count(col53) from r_table;r_table 消耗时间:55.743ms
c_table 消耗时间:34.023ms
查询20个字段消耗时间
select count(col1),count(col2),count(col4), count(col5),count(col7),count(col8),count(col9),count(col10),count(col11),count(col14),count(col18),count(col19),count(col20),count(col23),count(col24),count(col25),count(col30),count(col31),count(col32),count(col39) from r_tabler_table 消耗时间:62.746ms
c_table 消耗时间:34.048ms
查询50个字段消耗时间
select count(col1),count(col2),count(col4), count(col5),count(col7),count(col8),count(col9),count(col10),count(col11),count(col13),count(col14),count(col18),count(col19),count(col20),count(col23),count(col24),count(col25),count(col28),count(col29),count(col30),count(col31),count(col32),count(col35),count(col36),count(col38),count(col39),count(col40),count(col41),count(col42),count(col45),count(col46),count(col48),count(col49),count(col50),count(col52),count(col53),count(col55),count(col56),count(col58),count(col60) from r_table;r_table 消耗时间:119.231ms
c_table 消耗时间:25.986ms
查询全部字段消耗时间
select * from r_table- r_table 消耗时间:175.872ms
- c_table 消耗时间:187.226ms
- 可以发现,如果查询全部字段,则基本上没有优势
可视化为折线图为:
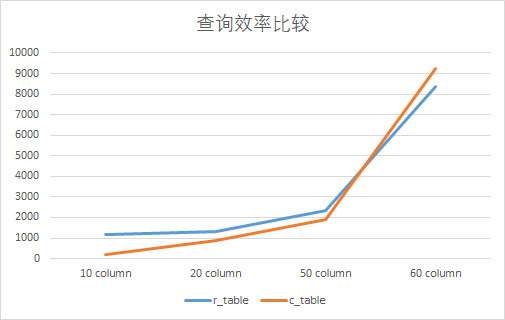
扩大数据集为50w,重新进行测试,得到结果为: